PoC Edge Manufacturing
Use-case overview
 Posted by Andrea Battaglia
on September 20, 2021 ·
39 mins read
Posted by Andrea Battaglia
on September 20, 2021 ·
39 mins read
Posted by Andrea Battaglia
on September 20, 2021 ·
39 mins read
Posted by Andrea Battaglia
on September 20, 2021 ·
39 mins read
The team has been listening to the Market needs and investments for quite a few months recently. In addition to that, we tried to understand what is the main trend in the innovation space, as well as the latest and greatest in terms of new projects and customer requests.
It came out that the manufacturing vertical is currently most invested vertical and we decided to try to address some common issues and questions regarding the architectural design and the most important collaterals such as security, workload distribution, connectivity and so on so forth.
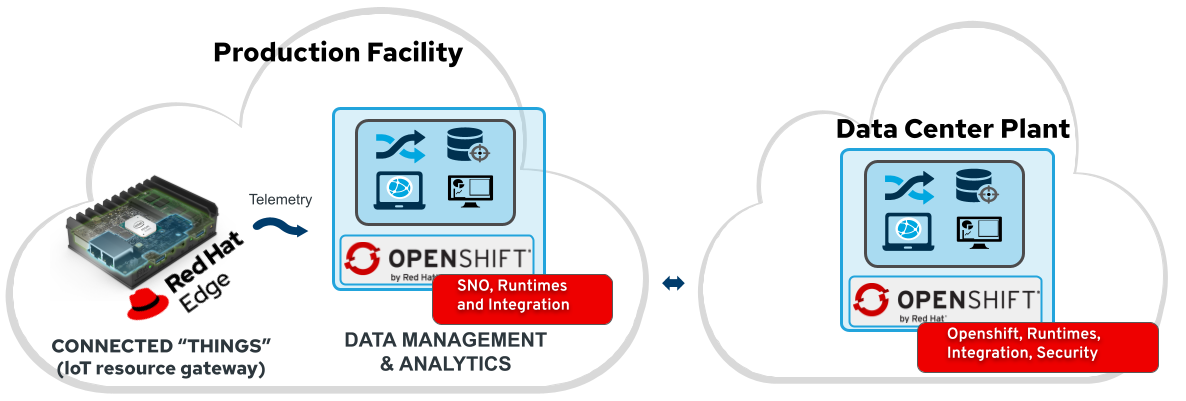
The main goal is to build an environmental network of machineries producing goods intended for the global market.
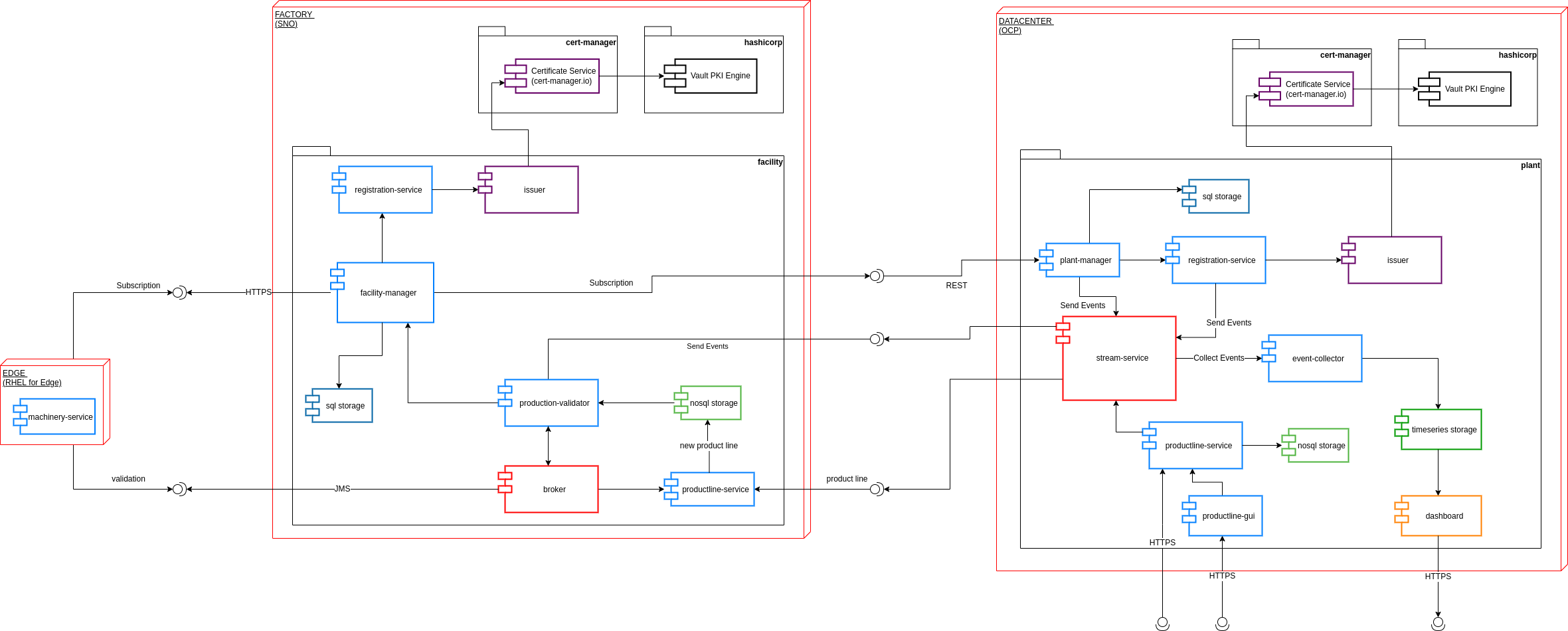
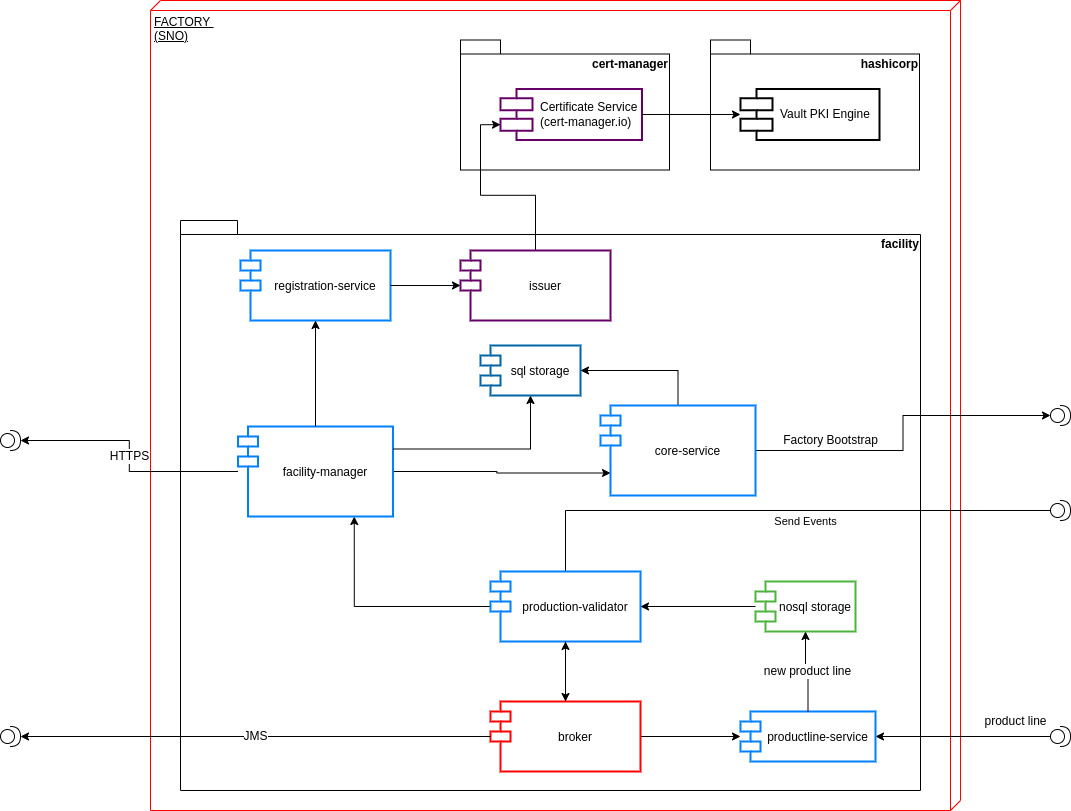
The machineries (edge devices) belong to a facility network environment identified as Factory (Edge Server). The factories are managed by the central plant manager, identified as Datacenter.
To be specific, the machineries produce t-shirts.
The item production is based on a production model (a.k.a. Product Line) and consists of four production stages, each and every of subject to validation against a 3rd party entity living on the Factory layer.
If the validation process returns a negative outcome, the item is marked as discarded and it’s production process is interrupted.
Each and every stage production and the related validation are documented through telemetry sends to the plant manager.
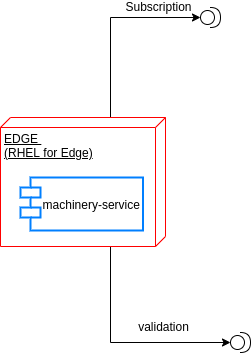
The software running on the edge device has the purpose of emulating a machinery producing T-shirts based on the production model provided by the factory controller.
The business logic of the Machinery has been entirely implemented using cloud-native frameworks and packaged using container technologies.

The Hardware of choice for the edge device is the Compulab Fitlet2.

The FITLET2-CE3930 is equipped with Intel® Atom X5-E3930 powered by Intel®.
Model |
FITLET2-CE3930-P36 |
Fan / Fanless |
Fanless |
CPU |
Intel® Atom x5-3930 |
RAM |
1x 2Gb SO-DIMM 204-pin DDR3L Non-ECC DDR3L-1866 (1.35V) |
Display |
Dual head: mini DP 1.2 4K @ 60 Hz; HDMI 1.4 4K @ 30 Hz |
WIFI |
802.11ac dual antenna + BT 4.2 |
Ethernet |
2 GbE ports on-board |
USB 2.0 |
4 USB ports on-board: 2x USB 3.0 + 2x USB 2.0 |
Audio |
Stereo line out Realtek ALC1150 audio codec |
Serial Port |
RS232 mini-serial |
BIOS |
AMI Aptio V |
Input voltage range |
Up to DC 9V – 36V* |
Operating system support |
all |
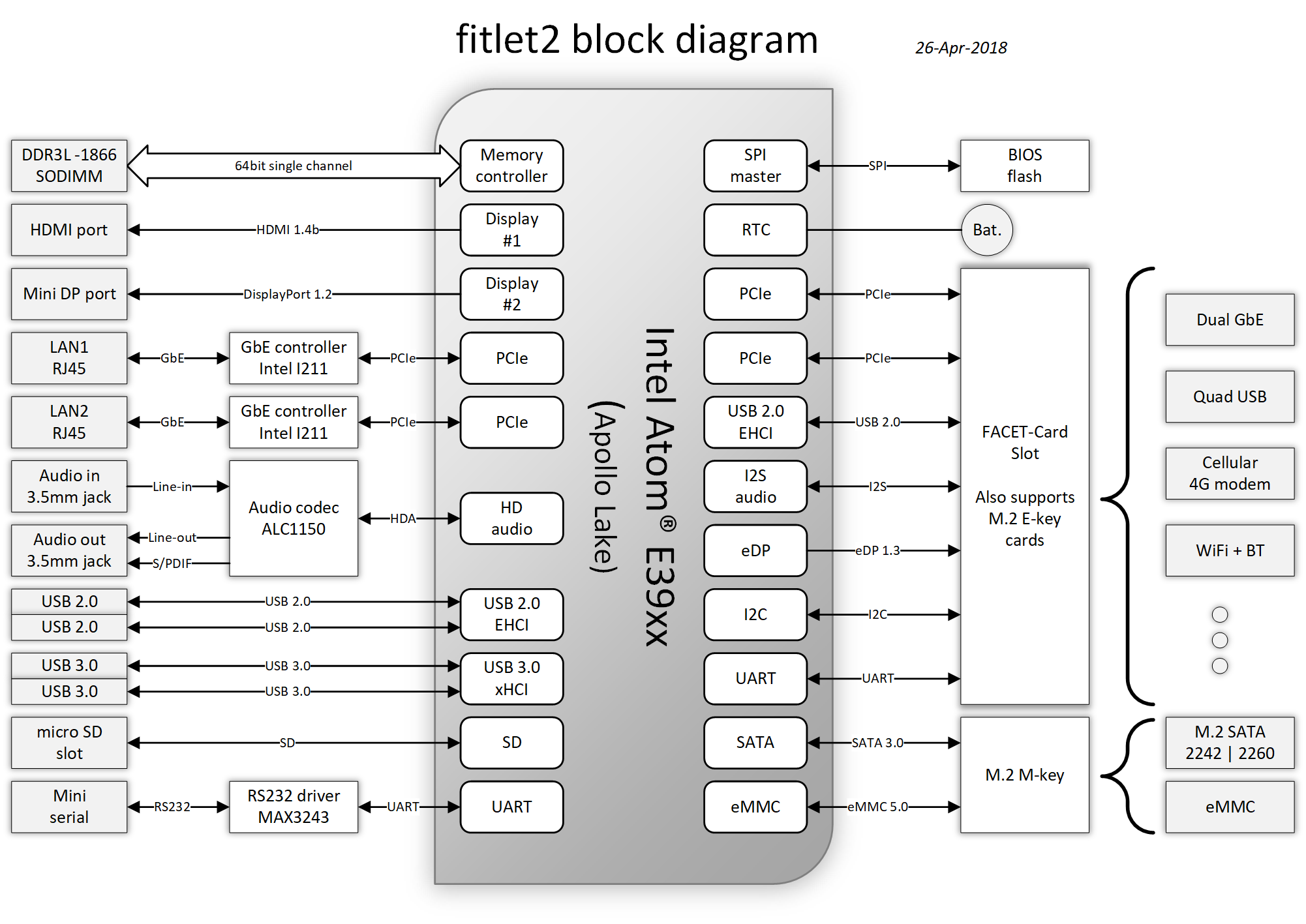
Additional technical detail can be found at the following link: link.
In an edge computing solution, the operating system is required to be efficient, lightweight and mature. The team focused on the most efficient enterprise-grade solution on the marker, which guarantees security, performance, and container-native solutions. Below a list of the principal, compulsory features we’ve been looking for in an operating system:
Must be fully-fledged 64 bit OS (not just its kernel);
Must have a very small memory footprint;
Must be immutable or, at least, modular;
Must have the ability to run a container engine with the minimum memory footprint, like Podman or CRI-O;
The most suitable and appropriate operating system, also certified on the target hardware is Red Hat Enterprise Linux for Edge (RHEL for Edge).
Podman is a daemonless, open source, Linux-native tool designed to develop, manage, and run Open Container Initiative (OCI) containers and pods.
It has a similar directory structure to Buildah, Skopeo, and CRI-O.
Podman doesn’t require an active container engine for its commands to work.
Last but not least, Podman is available in the standard rpm library of RHEL, so you get full support on it.
It’s implemented on top of the Quarkus framework and runs in native mode on a container environment.
The Machinery service is the core service of the edge device and implemented on top of the Quarkus framework. The service is compiled in native mode using MandrelVM to run natively into a container (possible on 64bit OS only!)
Moreover, the Machinery service is designed and implemented to have the smallest memory footprint as possible and perform the transactions with the API exposed by the Factory in the shortest time. The native mode dramatically improves the performance and guarantees the full compatibility with the OCI standards and the Podman engine.
The Machinery service is responsible for the emulation of a machinery producing T-shirts. The production process goes through four different stages each of the managed by a conveyor belt.
The production stages are enumerated here and can be listed as:
WEAVING
COLORING
PRINTING
PACKAGING
Each and every production stage generates a set of random numbers representing what’s been produced and that outcome is added to the Item data object and sent to the Production Validator service (Factory layer) for validation.
The Machinery service starts the production of a new T-shirt every 2 seconds and the execution of each and stage job takes a random amount of time between 1 and 2 seconds. The team is open to thoughts and suggestions about the opportunity/need to make that timeframe variable for performance testing purposes.
More details can be found in the dedicated repository.
The Edge Server is based on the powerful Intel® NUC 10 Performance kit - NUC10i7FNH.
The Intel® NUC guarantees performance and stability to the container platform designed to control the facility and the machineries.

Product Collection |
Intel® NUC Kit with 10th Generation Intel® Core™ Processors |
Board Number |
NUC10i7FNB |
Board Form Factor |
UCFF (4" x 4") |
Socket |
Soldered-down BGA |
# of Cores |
6 |
# of Threads |
12 |
Processor Base Frequency |
1.10 GHz |
Max Turbo Frequency |
4.70 GHz |
RAM |
DDR4-2666 1.2V SO-DIMM |
Internal Drive Form Factor |
M.2 and 2.5" Drive |
SSD |
M.2 256Gb |
Lithography |
14 nm |
TDP |
14 nm |
Lithography |
25 W |
DC Input Voltage Supported |
19 VDC |
Additional technical detail can be found at the following link: link.
Red Hat has worked a lot to make OpenShift footprint smaller to fit into more constrained environments by putting both control and worker capabilities into a single node.
Thanks to the capabilities and functionalities of Single Node Openshift (SNO) it is now possible to leverage the overall factory management and automation with less reaources and dedicate at scale dedicated business logic to the scale of the production facilities in a secured fashion.
The team is keen to provide a detailed walkthrough about How to install SNO on 10th gen NUC here
A-MQ Broker is a pure-Java multiprotocol message broker. It’s built on an efficient, asynchronous core with a fast native journal for message persistence and the option of shared-nothing state replication for high availability.
Persistence - A fast, native-IO journal or a JDBC-based store
High availability - Shared store or shared-nothing state replication
Advanced queueing - Last value queues, message groups, topic hierarchies, and large message support
Multiprotocol - AMQP 1.0, MQTT, STOMP, OpenWire, and HornetQ Core
Integration - Full integration with Red Hat JBoss EAP
A-MQ Broker is based on the Apache ActiveMQ Artemis project.
The broker service exposes the endpoint for the stage production telemetry coming from the machineries running on the edge devices. The endpoint is exposed through the Openwire protocol, protocol of choice for the implementation of transactional asynchronous architectures.
The broker offers dedicated queues for the production telemetry coming from the machineries and creates dedicated queues for the validation response from the validation service. More in detail, the broker service creates one queue for each and every machinery service awaiting for validation responses. Technical details about the telemetry and the endpoints to be given in the next chapters.
Cert-manager automates certificate management in cloud native environments and thus helped with the implementation of a dynamic certificate provisioning for edge devices
Cert-manager builds on top of Kubernetes, introducing certificate authorities and certificates as first-class resource types in the Kubernetes API.
This makes it possible to provide 'certificates as a service' to developers working within your Kubernetes cluster.
Highlights: Provide easy to use tools to manage certificates.
A standardised API for interacting with multiple certificate authorities (CAs).
Gives security teams the confidence to allow developers to self-server certificates.
Support for ACME (Let’s Encrypt), HashiCorp Vault, Venafi, self signed and internal certificate authorities.
Extensible to support custom, internal or otherwise unsupported CAs.
In our design, the issuer provides service (runtime) certificates to all the devices managed by the single factory. In order to achieve the above, the the factory performs the following actions at its bootstrap time:
The Factory registarts itself against the production plant.
In case of registration successful, the factory receives a unique certificate for the factory; The certificate will have the form od a Delegate CA
The Factory asks cert manager to instantiate a Delegate certificate Issuer using the above delegate certificate authority as a root certificate.
The factory will issue runtime certificate to the edge devices registering against the factory using the newly created issuer
PostgreSQL is a powerful, open source object-relational database system with over 30 years of active development that has earned it a strong reputation for reliability, feature robustness, and performance.
The relational database engine is used to store non-timeseries data like:
Machinery data
More about PostgreSQL can be found here.
MongoDB’s document data model naturally supports JSON and its expressive query language is simple for developers to learn and use. Functionality such as automatic failover, horizontal scaling, and the ability to assign data to a location are built-in.
The nosql database service is helpful when it comes to store, query and retrieve structured data sets like the json version of the Product Line model.
It’s implemented on top of the Quarkus framework and runs in native mode on a container environment.
The Facility Manager service is the core service of the factory layer.
It is responsible for the management of the following entities in the facility:
The factory;
The machineries;
The machinery service also covers a few operational functionalities like:
Device subscription (pass-through);
Certificates distribution (pass-through);
Factory ID provider for all the services belonging to the same layer.
At bootstrap time, the Facility Manager subscribes to the Central subscription system on the datacenter, providing its identity info (Serial ID and Name). it will receive, in turn, a unique ID (in a format of a UUID) that each and every service running on the factory layer will use when connecting to the services running on the datacenter.
The response from the Plant Manager service will also contain the certificates used for mutual authentication against services running on the datacenter.
The specs of the services exposed by the Facility Manager service can be found into the dedicated section.
More details can be found in the dedicated repository.
It’s implemented on top of the Quarkus framework and runs in native mode on a container environment.
The Product-line service is responsible for transforming the Global Product-line into a model that supposed to be consumed by the Machineries.
The transformation phase consists of a few simple steps:
The main goal of the above functionality is to create a product line model that, merged with the margins, extends the range of possible values for the emulation (rundom number generators) performed by the Machinery service. That, in turn, will generate a certain percentage of values not belonging to the original range of values.
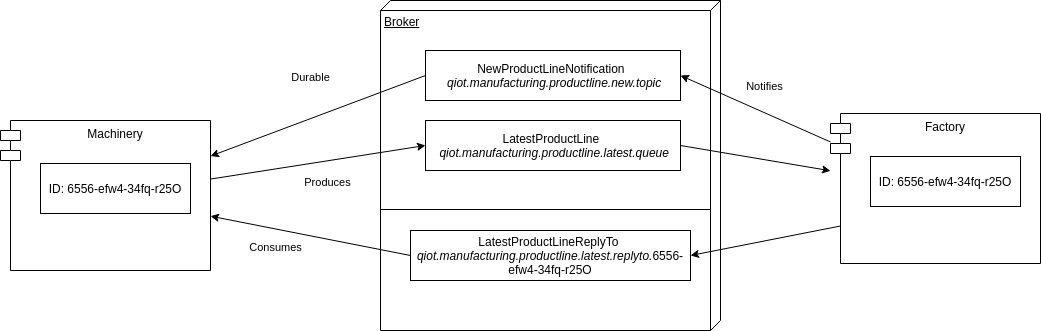
More details can be found in the dedicated repository.
It’s implemented on top of the Quarkus framework and runs in native mode on a container environment.
The Validator service is responsible for the validation of the outcome of each and every production stage performed by the Machinery service.
It relies on the Product-Line service to gather the info related to the Product-line model and communicate asynchronously with the machineries through the Broker service.
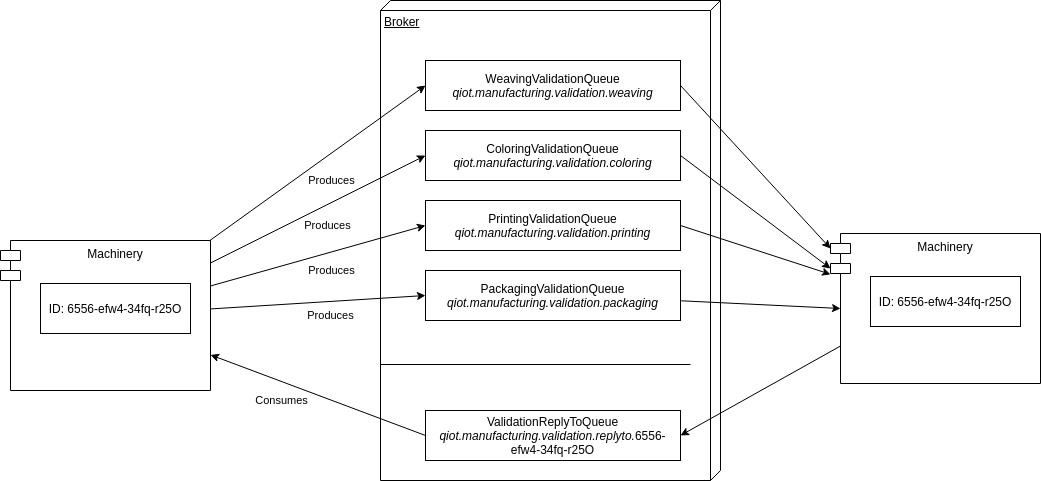
More details can be found in the dedicated repository.
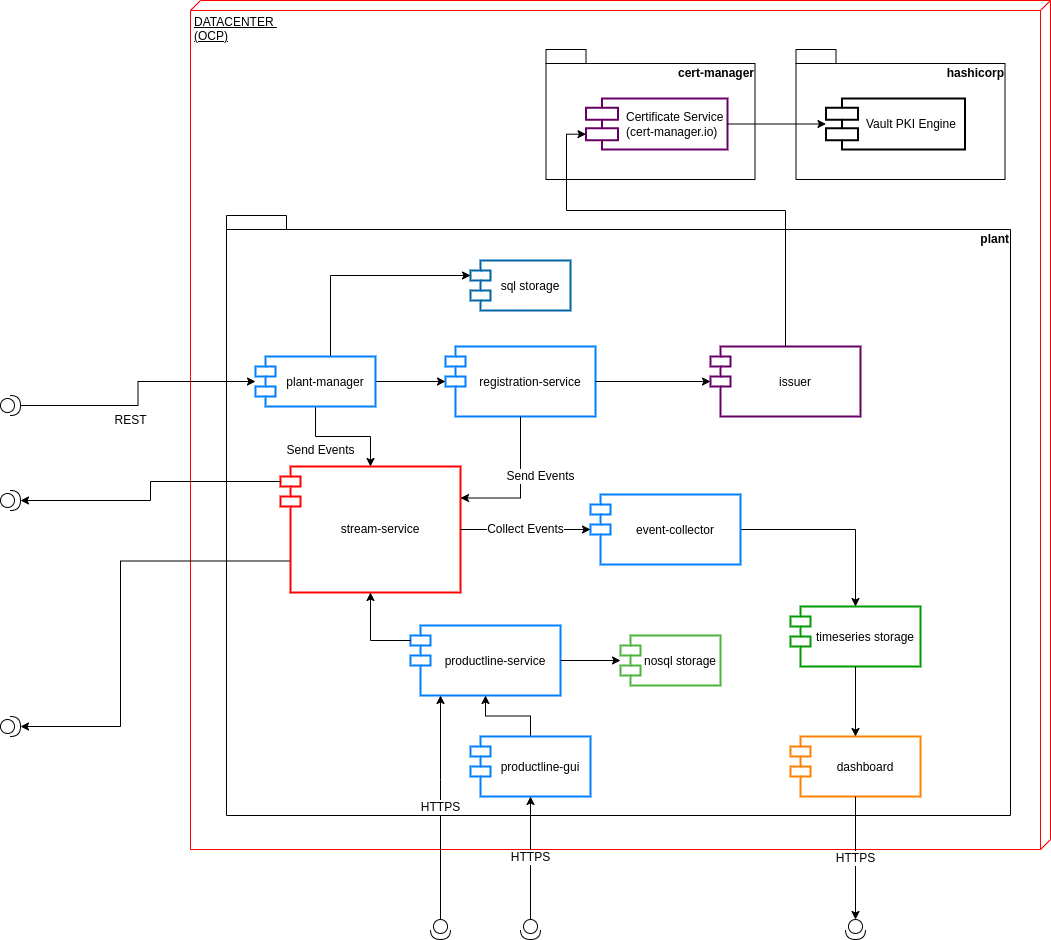
The Datacenter layer of the Manufacturing use-case has been designed and implemented by the team and is made up of several services and business logic to manage, store, aggregate and retrieve data.
The infrastructure of the QIoT project must have flexible imprinting and should be easily scalable both horizontally and vertically.
To fulfill the scalability requirements a Cloud-based platform is needed.
A graphical representation of the basic Infrastructure Architecture:
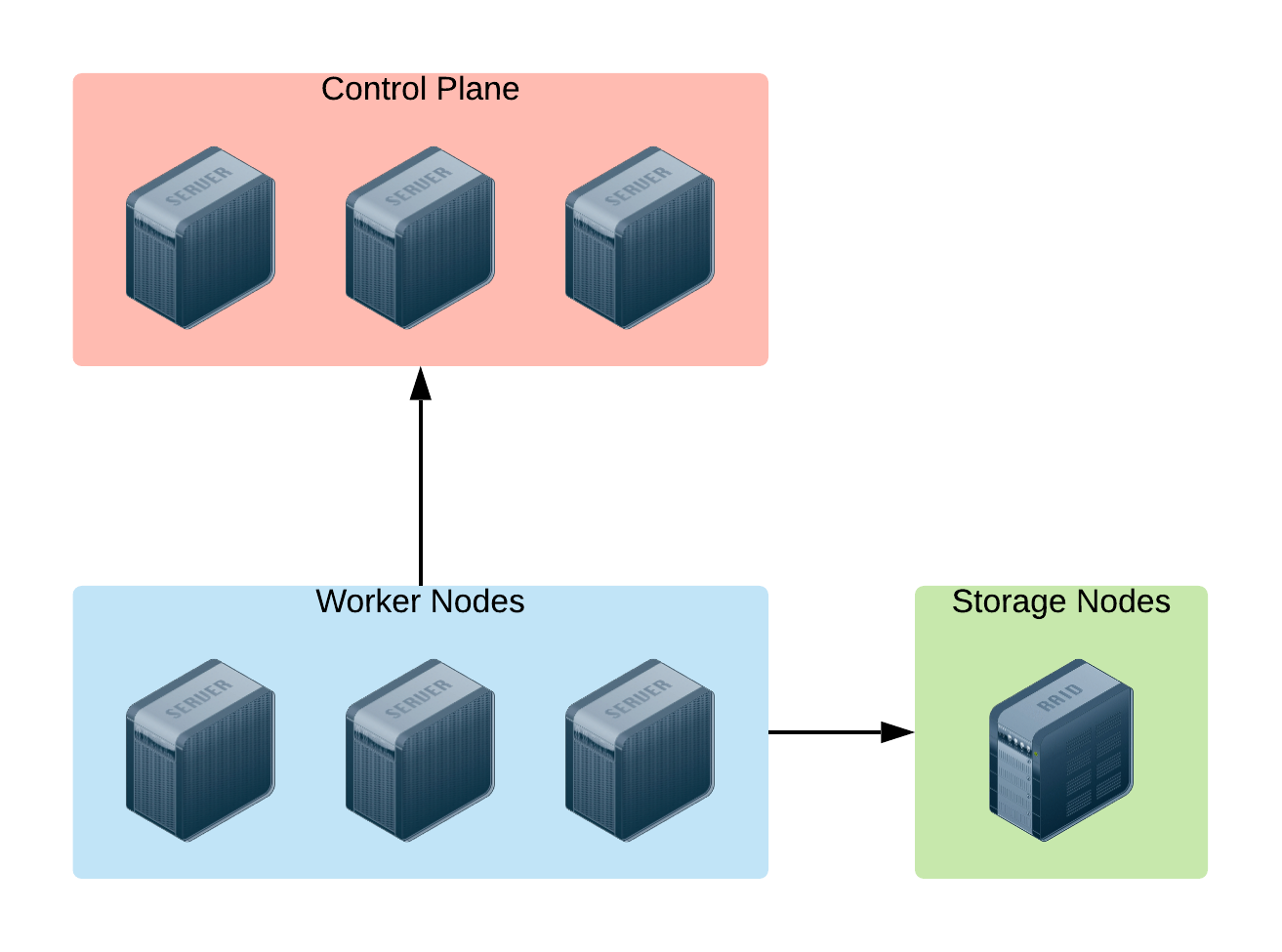
Based on the image above, here is the sizing of the infrastructure provisioned for the Openshift Container Platform:
OCP Control Plane (master nodes)
#Servers: 3
CPUs: 8
RAM: 24G
OCP Worker Nodes:
#Servers: 3
CPUs: 12
RAM: 64GB
Storage Server: provides storage functionality to the infrastructure to store data safely and consistently on the disk. There’s no urgent/compulsory need to add this component to the infrastructure architecture, at least at the early stage of the project, because the basic amount of storage provided by the cloud platform would definitely cover all the needs described.
Some additional storage will be needed in case of extended lifetime and participation in the project (i.e. lots more data arriving at the Data Hub). Anyway, just making use of the storage layer from the cloud provider of choice and installing Openshift Container Storage on top of it will guarantee horizontal scalability and data consistency all over the container platform out of the box.
Vertical scalability is guaranteed by the could platform. Horizontal scalability is guaranteed by Openshift by using the auto-scaling feature embedded in the container platform.
Red Hat OpenShift is the hybrid cloud platform of open possibility: powerful, so you can build anything and flexible, so it works anywhere.
Adopting the Openshift container platform made us save tons of hors implementing features and behaviors supposed to be home cooked, otherwise:
Native pipelines using Tekton
One-shot installation using Helm charts
2-day operations using Operator Framework
Container storage
Security and Isolation
Automate cluster scalability
More about Openshift Container Platform can be found here.
In the forecast of the need for receiving/handling a large number of concurrent messages, A-MQ Streams is the component of choice for streaming messages through the integration and the storage layers.
An internal streaming service guarantees scalability and reliability of the message flow management within the Datacenter business logic.
The Stream service topics serve a variety of functionalities and processes impacting the following workflows:
Product-line: New Global product-line are delivered to the streaming service for asyncronous consumption by the factories. This workflow requires persistence and off-set management, both provided by the A-MQ Streams product;
Telemetry: A-MQ perfectly fits into the canonical usecase of telemetry stream and management. Compared to the previous use-case implemented by the community, the team decided to go for a more structured and scalable approach based on a could-native product, rather that just relying on a communication protocol like MQTT protocol.
The implementation choices above make it easy to fine tune the connections, the scalability, the message flow, and retention separately.
This design makes it a lot easier to decouple the implementation details of the integration services responsible for offloading (consuming messages from) every topic and storing the values into the storage tier, improving horizontal scalability.
More about A-MQ Streams can be found here.
Timeseries database engines are the technology of choice to store the telemetry coming from the IoT devices in an Edge Computing scenario.
For this use-case the team has picked up Influxdb, as it guarantees scalability, reliability and a level of performances not achievable using other competitors on the market.
Moreover, InfluxDB is the essential time series toolkit — dashboards, queries, tasks and agents all in one place.
As well as for the previous software infrastructure components used to receive and stream data, we have decided to go for a separation by telemetry-time.
The Timeseries Storage hosts the data relative to one telemetry only:
More about InfluxDB can be found here.
PostgreSQL is a powerful, open source object-relational database system with over 30 years of active development that has earned it a strong reputation for reliability, feature robustness, and performance.
The relational database engine is used to store non-timeseries data like:
Factory-related data
Machinery-related data
More about PostgreSQL can be found here.
MongoDB’s document data model naturally supports JSON and its expressive query language is simple for developers to learn and use. Functionality such as automatic failover, horizontal scaling, and the ability to assign data to a location are built-in.
The nosql database service is helpful when it comes to store, query and retrieve structured data sets like the json version of the Global Product-line model.
Cert-manager automates certificate management in cloud native environments and thus helped with the implementation of a dynamic certificate provisioning for edge devices
cert-manager builds on top of Kubernetes, introducing certificate authorities and certificates as first-class resource types in the Kubernetes API.
This makes it possible to provide 'certificates as a service' to developers working within your Kubernetes cluster.
Highlights
Provide easy to use tools to manage certificates.
A standardised API for interacting with multiple certificate authorities (CAs).
Gives security teams the confidence to allow developers to self-server certificates.
Support for ACME (Let’s Encrypt), HashiCorp Vault, Venafi, self signed and internal certificate authorities.
Extensible to support custom, internal or otherwise unsupported CAs.
More about out cert-manager implementation here
More about Cert-Manageranager can be found here.
Below you can find an overview of our distributed certificate authority implementation (using the Delecate CA described in the previous chapter)
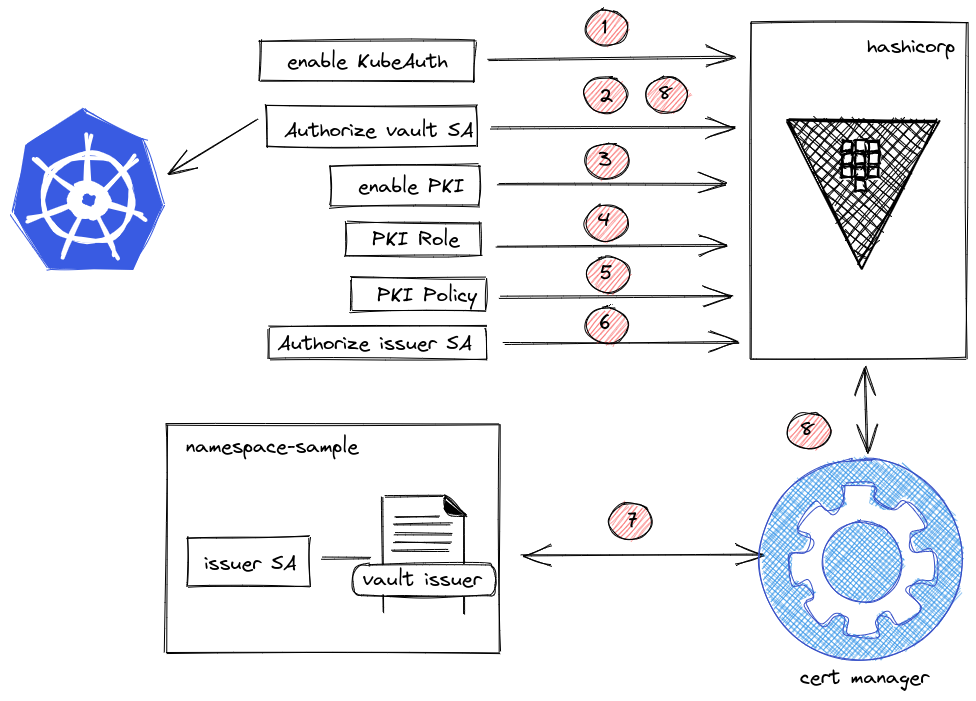
Enable Kubernetes Auth Engine in Vault.
Authorize Vault SA in k8s to Token Review.
Enable PKI engine.
Configure PKI role name in Vault.
Configure PKI policy in Vault.
Authorize/Binding issuer SA to use (policy) the PKI role.
Create Vault Issuer in app namespace with issuer SA.
Cert Manager validates the credentials of the issuer against Vault.
The Datacenter business logic is built on top of Quarkus framework. All the services run natively on top of the container technology and benefit from the features from the Serverless architecture.
A separate discussion must be done for the Dashboard, which exposes diagrams based on the telemetry coming from the measurement stations and in implemented on top of RedHat build of Node.js
It’s implemented on top of the Quarkus framework and runs in native mode on a container environment.
It’s responsible for the provisioning and maintainance of the certificates used by services to connect to the other layers of the architecture using the mutual authentication method.
The main goal of the registration service is to implement a façade between the Plant Manager service and the Cert-manager service. To achive this goal and to make the access to the service limited, the service is not exposed by the router.
The interaction between the registration service and the Cert-manmager service is supported by the fabric8 Kubernetes plugin
More details can be found in the dedicated repository.
It’s implemented on top of the Quarkus framework and runs in native mode on a container environment.
It’s responsible for the management of the overall landscape:
Factories subscribe to the plant-manager and obtain a unique UUID and a trust store containing both the certificates for the connection to the datacenter and from the Machineries;
Machineries subscribe to the facility manager service which, in turn, forwards the request to the plant manager service. They Obtain a unique UUID and a trust store containing the certificates to connect to the services exposed by the Factory layer.
Landscape data are stored in the SQL Storage to take advantage of the CRUD operations.
Moreover, the service makes use of the 2nd level cache to speed up the read operations.
It exposes a rest API secured with mutual authentication. Details about the exposed endpoints are available in the [Specs] section
More details can be found in the dedicated repository.
It’s implemented on top of the Quarkus framework and runs in native mode on a container environment.
The Global Product-line service is responsible for managing the Product-line models at the central level. The service can either:
Generate a new random Global Product-line;
Receive one from the GUI (not yet implemented) through REST API.
The Product-line model is validated and stored into the SQL Storage.
More details can be found in the dedicated repository.
This service is responsible for consuming the telemetry coming from the Stream service.The consumed paylod gets calidated, eventually decorated or adapted, and finally stored into the Timeseries Storage.
The team decided to go for a pure microservice implementation, dedicating one service to each and every telemetry type. Thus, all the services belonging to the event-collector family must extend some common abstract components that can be found into the Commons repositories (qiot-manufacturing-datacenter-utilities) and must be implemented adhering to the microservices atomicity, scalability and isolation recommended practices. Creating additional serviecs to handle different types of telemetries is left to the audience ;-)
Thanks to the Commons module it’s easy to extend the group of services to make them accept an additional telemetry type;
As the frequency of incoming messages per telemetry type can vary, scaling feature affects only one service in the group;
Due to the incompatibility of the Java Client for InfluxDB with Quarkus native mode, the service is compiled using the standard java fast-jar mode.
More details can be found in the dedicated repository.